딥러닝을 이용한 법률 분야 한국어 의미 유사판단에 관한 연구
기존의 데이터 검색 방법으로는 키워드 중심의 검색 방법이 주로 사용되나, 이는 전문적인 용어가 많이 쓰이는 법률 분야의 검색 방법으로는적합하지 않다. 이에 대해 본 논문에서는 법률 분야
www.kci.go.kr
주요 키워드 : 자연어처리, 리걸테크, Semantic Similarity, BERT, 법률
0. 요약

1. 서론
전문 용어에 익숙하지 않은 일반인들에게는 적합하지 않은 문제
1. 리걸 테크 : 법률 도메인 문장에 자연어 처리 기술 적용 -> 문장간 유사성 판단의 최적화 임베딩 방법을 제공
2. BERT 기반 전이학습
2.2 BERT
BERT 모델의 사전학습 태스크
1. 마스크 언어모델 : 토큰 일부를 마스킹, 빈칸으로 대체 -> 모델이 빈칸을 채우게 만들게 함
2. NSP(Next Sentence Prediction) : 두 문장이 이어진 문장인지 아닌지를 반복 비교
2.3 TF-IDF
TF : 해당문서내 출현빈도로 중요도 계산 -> 높을수록 중요
DF : 전체 문서에서 출현하는 빈도로 중요도 계산 -> 낮을수록 중요
2.4 Universal Sentence Encoder
USE
- 문장단위 임베딩 o
- 단어단위 임베딩 x
3. 법률 분야 의미 유사판단 데이터셋
데이터셋 갯수 : 40,475개
Train, Test split ratio : 0.8
X 인자 : sent1, sent2, category
Y 인자 : label (0 또는 1)
입력데이터 : "사용자가 원하는 문장"
4.1 TF-IDF를 이용한 키워드 기반 임베딩

전처리 방법으로는 형태소 분석기(MeCab) 활용 -> 명사 추출

코사인유사도 (0 ~ 1) 로 유사도 확인
4.2 USE를 이용한 의미 기반 임베딩

거리가 아웃풋으로 나오기에, 유사도 = 1 - 거리 로 환산한다.
4.3 실험방법
추가 임베딩 - BERT

전이학습 : TF-iDF 또는 USE를 활용한 워드임베딩 후, 유사도 상위 n개 추출

추출된 n개에 대한 BERT 이진 분류

이진 분류 결과 1인 경우, 유사도 랭크 재정렬
5. 실험 결과
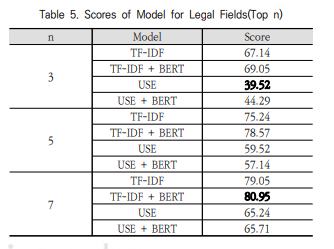
TF-iDF + BERT가 n개의 갯수와 상관없이 가장 높은 성능을 기록
6.1 TF-IDF vs USE

TF-iDF : 단어 자체에 가중치가 높다.
USE : 단어 자체에 가중치가 크지 않고, 동음이의어 등 문맥적인 유사성에 가중치가 높다.
6.2 TF-IDF vs TF-IDF + BERT


문장의 길이가 짧은 경우, TF-iDF가 가지는 문제를 BERT와의 결합으로 보완했다.
7. 결론

TF-iDF + BERT 조합이 가장 파워풀하다.